
Classification et analyse des images
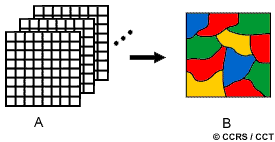
Un analyste qui tente de classer les caractéristiques d'une image, utilise les éléments de l'interprétation visuelle (discutés à la section 4.2) pour identifier des groupes homogènes de pixels qui représentent des classes intéressantes de surfaces. La classification numérique des images utilise l'information spectrale contenue dans les valeurs d'une ou de plusieurs bandes spectrales pour classifier chaque pixel individuellement. Ce type de classification est appelé reconnaissance de regroupements spectraux. Les deux façons de procéder (manuelle ou automatique) ont pour but d'assigner une classe particulière ou thème (par exemple : eau, forêt de conifères, maïs, blé, etc.) à chacun des pixels d'une image. La "nouvelle" image qui représente la classification est composée d'une mosaïque de pixels qui appartiennent chacun à un thème particulier. Cette image est essentiellement une représentation thématique de l'image originale.
Lorsqu'on parle de classes, il faut faire la distinction entre des classes d'information et des classes spectrales. Les classes d'information sont des catégories d'intérêt que l'analyste tente d'identifier dans les images, comme différents types de cultures, de forêts ou d'espèce d'arbres, différents types de caractéristiques géologiques ou de roches, etc. Les classes spectrales sont des groupes de pixels qui ont les mêmes caractéristiques (ou presque) en ce qui a trait à leur valeur d'intensité dans les différentes bandes spectrales des données. L'objectif ultime de la classification est de faire la correspondance entre les classes spectrales et les classes d'information. Il est rare qu'une correspondance directe soit possible entre ces deux types de classes. Des classes spectrales bien définies peuvent apparaître parfois sans qu'elles correspondent nécessairement à des classes d'information intéressantes pour l'analyse. D'un autre côté, une classe d'information très large (par exemple la forêt) peut contenir plusieurs sous-classes spectrales avec des variations spectrales définies. En utilisant l'exemple de la forêt, les sous-classes spectrales peuvent être causées par des variations dans l'âge, l'espèce, la densité des arbres ou simplement par les effets d'ombrage ou des variations dans l'illumination. L'analyste a le rôle de déterminer de l'utilité des différentes classes spectrales et de valider leur correspondance à des classes d'informations utiles.
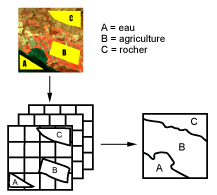
Les méthodes de classification les plus communes peuvent être séparées en deux grandes catégories : les méthodes de classification supervisée et les méthodes de classification non supervisée. Lors de l'utilisation d'une méthode de classification supervisée, l'analyste identifie des échantillons assez homogènes de l'image qui sont représentatifs de différents types de surfaces (classes d'information). Ces échantillons forment un ensemble de données-tests. La sélection de ces données-tests est basée sur les connaissances de l'analyste, sa familiarité avec les régions géographiques et les types de surfaces présents dans l'image. L'analyste supervise donc la classification d'un ensemble spécifique de classes. Les informations numériques pour chacune des bandes et pour chaque pixel de ces ensembles sont utilisées pour que l'ordinateur puisse définir les classes et ensuite reconnaître des régions aux propriétés similaires à chaque classe. L'ordinateur utilise un programme spécial ou algorithme afin de déterminer la "signature" numérique de chacune des classes. Plusieurs algorithmes différents sont possibles. Une fois que l'ordinateur a établi la signature spectrale de chaque classe à la classe avec laquelle il a le plus d'affinités. Une classification supervisée commence donc par l'identification des classes d'information qui sont ensuite utilisées pour définir les classes spectrales qui les représentent.
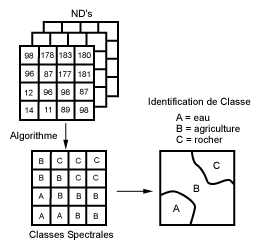
La classification non supervisée procède de la façon contraire. Les classes spectrales sont formées en premier, basées sur l'information numérique des données seulement. Ces classes sont ensuite associées, par un analyste, à des classes d'information utile (si possible). Des programmes appelés algorithmes de classification sont utilisés pour déterminer les groupes statistiques naturels ou les structures des données. Habituellement, l'analyste spécifie le nombre de groupes ou classes qui seront formés avec les données. De plus, l'analyste peut spécifier certains paramètres relatifs à la distance entre les classes et la variance à l'intérieur même d'une classe. Le résultat final de ce processus de classification itératif peut créer des classes que l'analyste voudra combiner, ou des classes qui devraient être séparées de nouveau. Chacune de ces étapes nécessite une nouvelle application de l'algorithme. L'intervention humaine n'est donc pas totalement exempte de la classification non supervisée. Cependant, cette méthode ne commence pas avec un ensemble prédéterminé de classes comme pour la classification supervisée.
Le saviez-vous?
« ...Cette image a une belle texture, qu'en pensez-vous?... »

...La texture a été identifiée comme étant un élément clé de l'interprétation visuelle (section 4.2), particulièrement dans l'interprétation des images radars. Des algorithmes de classification des textures numériques sont aussi disponibles et peuvent être une alternative (ou un complément) à la classification spectrale. Ces algorithmes fonctionnent de façon semblable à l'application d'un filtre spatial ; des calculs sont effectués sur les données d'une image se retrouvant sous une « fenêtre » qui se déplace ensuite jusqu'à ce que l'image entière soit traitée. Ces calculs servent à estimer la « texture » de l'image en fonction de la variabilité des valeurs numériques des pixels sous la fenêtre. Plusieurs mesures de la texture peuvent être faites afin de faire la différence entre les caractéristiques et définir les propriétés de la texture de l'image.
Question éclair
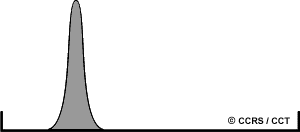
Supposez que vous vouliez effectuer une classification sur les données d'une image satellitaire. Cependant, lorsque vous regardez l'histogramme de l'image, vous vous apercevez que toutes les données utiles sont réparties sur un intervalle restreint de valeurs. Serait-il bon d'effectuer un rehaussement linéaire du contraste avant de commencer la classification?
La réponse est...
Question éclair - réponse
Le rehaussement d'une image est utilisé exclusivement pour pouvoir apprécier et analyser visuellement une image. Un rehaussement n'ajoutera rien d'utile du point de vue de la classification d'une image. Voici une autre façon d'expliquer cette réponse : si deux pixels ont une valeur numérique d'intensité séparée par un seul niveau, il est difficile de faire la différence à l'oeil nu entre les deux pixels.
Cependant, pour un ordinateur, cette différence de 1 est aussi évidente qu'une différence de 100. L'image rehaussée peut aider l'analyste à sélectionner les groupes-tests à l'oeil, mais la classification sera effectuée sur les données initiales non rehaussées.
Détails de la page
- Date de modification :